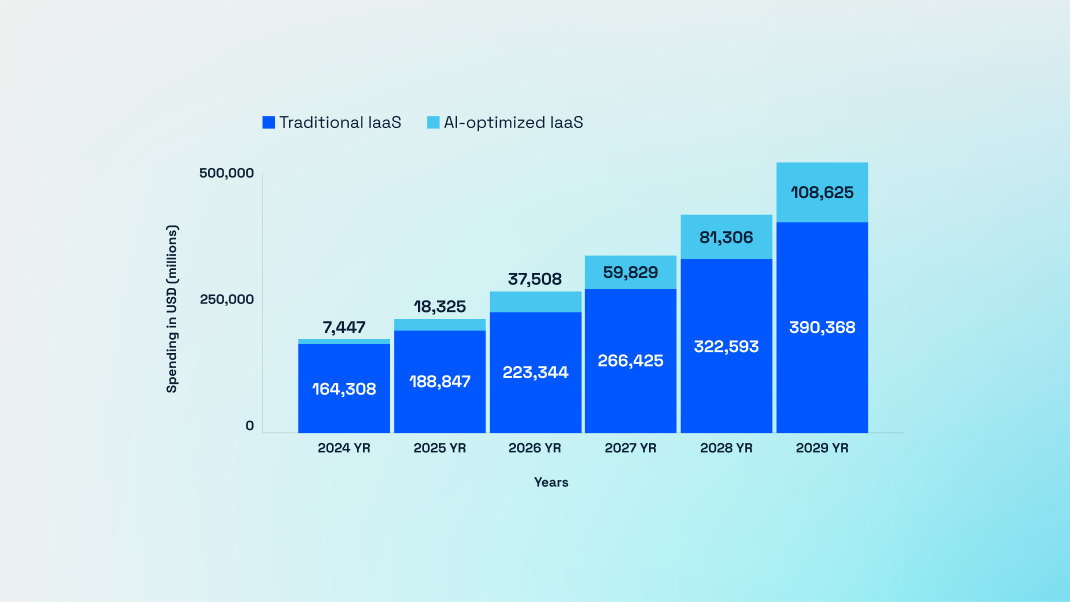
Gartner's latest projections reveal a seismic shift in cloud infrastructure spending: AI-optimized Infrastructure-as-a-Service (IaaS) will surge 146% to reach $37.5 billion by 2026, while traditional IaaS growth slows to single digits. This dramatic divergence signals that AI has become the primary driver of infrastructure investment, fundamentally transforming data center economics and creating unprecedented opportunities—and challenges—for infrastructure providers.
AI-optimized IaaS refers to cloud infrastructure specifically designed and configured for artificial intelligence workloads, distinct from general-purpose computing. Key differentiators include:
Specialized Hardware: GPU clusters (NVIDIA H100s, B200s), custom AI accelerators (Google TPUs, Amazon Trainium, Microsoft Maia), high-bandwidth memory (HBM for faster data access), and ASIC-based inference engines.
High-Performance Networking: 400G, 800G, and 1.6T Ethernet fabrics, low-latency InfiniBand interconnects, RDMA (Remote Direct Memory Access) for GPU-to-GPU communication, and specialized network topologies (fat-tree, Clos networks).
Massive Storage Systems: Parallel file systems handling petabytes of training data, NVMe SSD arrays for fast random access, object storage for model checkpoints and datasets, and tiered storage balancing performance and cost.
Optimized Software Stacks: Container orchestration for distributed training (Kubernetes, Slurm), ML frameworks optimized for specific hardware, distributed training libraries (Horovod, DeepSpeed), and monitoring and observability tools.
Why is AI-optimized IaaS growing so explosively while traditional IaaS matures? Several factors converge:
Enterprise AI Adoption: Companies across every sector are deploying production AI systems—not just experimentation. Manufacturing uses AI for quality control and predictive maintenance. Healthcare deploys AI for diagnostics and drug discovery. Financial services use AI for fraud detection and algorithmic trading. Retail applies AI for personalization and inventory optimization. Telecommunications leverage AI for network optimization.
Model Size Explosion: AI models are growing exponentially larger. GPT-3 (175B parameters) seemed massive in 2020. Today's largest models exceed 1 trillion parameters. Training these models requires infrastructure orders of magnitude beyond traditional computing.
Training Frequency: Organizations aren't training models once—they're continuously retraining on fresh data, fine-tuning for specific applications, running extensive hyperparameter searches, and maintaining multiple model versions. This multiplies infrastructure demand beyond one-time training costs.
Inference at Scale: While training gets attention, inference (actually using AI models) consumes far more infrastructure at scale. A chatbot serving millions of users, computer vision systems analyzing billions of images, recommendation engines processing endless user interactions, and fraud detection evaluating every transaction all require massive inference infrastructure.
Hybrid and Multi-Cloud: Organizations are using multiple cloud providers for AI—leveraging Google's TPUs for some workloads, NVIDIA GPUs on AWS for others, Azure for enterprise integration. This multi-cloud approach accelerates overall market growth.
Gartner reports a troubling trend: 61% of organizations cite talent shortages in managing specialized infrastructure, up from 53% earlier. As AI infrastructure grows more complex, the skills gap widens.
Organizations struggle to find expertise in GPU cluster management, distributed training optimization, AI network architecture, cost optimization for AI workloads, and security for AI systems and data.
This talent shortage creates multiple impacts: delayed AI deployments, suboptimal infrastructure utilization (wasting expensive resources), security vulnerabilities, higher costs from inefficient architectures, and competitive disadvantage versus organizations with necessary expertise.
Organizations are increasing AI infrastructure spending across categories:
Servers: 20% increase - high-end compute servers with GPUs/acceleratorsGPUs and Accelerators: 20% increase - NVIDIA, AMD, custom AI chipsStorage Systems: 19% increase - high-performance storage for training dataNetworking Equipment: 18% increase - high-bandwidth, low-latency fabrics
This balanced spending across infrastructure components reflects AI's comprehensive requirements—it's not just about GPUs; it's about entire systems optimized for AI workloads.
AI infrastructure economics differ dramatically from traditional computing:
Capital Intensity: AI infrastructure costs 5-10x more per rack than traditional computing. A rack of H100 GPUs costs $500,000-$1,000,000 versus $50,000-$100,000 for traditional servers.
Power Consumption: AI racks consume 40-80kW versus 5-10kW for traditional racks, multiplying power and cooling costs.
Utilization Criticality: Given massive costs, maximizing GPU utilization becomes essential. Idle GPUs waste enormous capital, driving demand for orchestration and scheduling expertise.
ROI Timelines: While expensive, AI infrastructure can deliver extraordinary ROI when applied to high-value problems—fraud prevention, drug discovery, autonomous vehicles. This justifies costs despite sticker shock.
Different regions show distinct AI infrastructure adoption patterns:
North America: Leads in AI-optimized IaaS adoption, driven by hyperscalers (AWS, Azure, Google Cloud) and tech giants. Silicon Valley, Seattle, and emerging hubs like Austin concentrate AI infrastructure.
Europe: Growing rapidly but facing energy cost challenges and regulatory complexity. GDPR and data sovereignty requirements drive regional infrastructure builds. Nordic countries attract data centers through renewable energy and cool climates.
Asia-Pacific: China's massive AI investments rival North America. Singapore, despite limited space, is a regional hub. India's growing AI sector drives infrastructure demand.
Middle East: UAE and Saudi Arabia are investing heavily in AI infrastructure, leveraging abundant solar power potential, available capital, strategic location, and government support.
The AI-optimized IaaS market shows interesting competitive dynamics:
Hyperscalers Dominate: AWS, Microsoft Azure, and Google Cloud lead through massive infrastructure investments, custom AI silicon (reducing dependence on NVIDIA), integrated ML platforms, and global scale.
Specialized Providers Emerge: CoreWeave, Lambda Labs, and others focus exclusively on AI infrastructure, offering flexibility and performance exceeding general-purpose clouds, attracting customers seeking GPU-optimized solutions.
On-Premises Renaissance: Some organizations are building dedicated AI infrastructure on-premises for data sovereignty and control, cost optimization at scale, performance predictability, and regulatory compliance.
Hybrid Models: Many enterprises use hybrid approaches—development and experimentation in cloud, production training on-premises, inference distributed across cloud and edge.
AI infrastructure's explosive growth creates environmental concerns. Data centers' energy consumption, cooling requirements, water usage (for evaporative cooling), and electronic waste all scale with AI infrastructure growth.
The industry is responding through renewable energy procurement, liquid cooling technologies, AI-optimized chip designs, and workload optimization software, but sustainability remains a critical challenge requiring continued innovation.
Given AI infrastructure costs, organizations are adopting various optimization strategies:
Spot Instances: Using discounted, interruptible compute for fault-tolerant training workloads, reducing costs 60-80% versus on-demand pricing.
Model Optimization: Techniques like quantization, pruning, and distillation reduce computational requirements without sacrificing accuracy.
Automated Scheduling: Intelligent schedulers pack workloads efficiently, maximizing GPU utilization and minimizing idle time.
Right-Sizing: Matching infrastructure to workload requirements rather than over-provisioning, using profiling tools to identify actual needs.
Reserved Capacity: Committing to long-term capacity for predictable workloads, achieving 30-50% discounts versus on-demand.
The path to $37.5 billion in 2026 will be shaped by several factors:
Technology Evolution: Next-generation GPUs and accelerators improving price-performance, enabling more capable models at lower cost.
Platform Maturation: ML platforms becoming more user-friendly, abstracting infrastructure complexity and expanding the developer base.
Edge AI Growth: Inference moving closer to data sources, distributing infrastructure demand beyond centralized data centers.
Regulatory Impacts: AI regulations potentially affecting infrastructure requirements, data residency, and model transparency.
Economic Conditions: Potential economic headwinds could slow AI investment, though strategic importance may insulate spending.
The 146% surge in AI-optimized IaaS spending to $37.5 billion by 2026 represents more than a market trend—it's a fundamental restructuring of computing infrastructure around artificial intelligence. Traditional general-purpose computing is maturing while AI-specific infrastructure becomes the new growth engine.
For infrastructure providers, this represents massive opportunity but requires substantial capital investment, technical expertise, and risk tolerance. For enterprises, AI infrastructure decisions become strategic imperatives affecting competitive positioning.
The winners in this transformation will be those who successfully navigate the complexity of AI infrastructure—balancing performance, cost, sustainability, and talent constraints while delivering business value that justifies extraordinary investments.
The AI revolution depends fundamentally on infrastructure. The $37.5 billion question is whether we can build enough, fast enough, efficiently enough, and sustainably enough to realize AI's transformative potential.